算法篇——堆排序
堆排序算法是由罗伯特·弗洛伊德(Robert W.Floyd)和威廉姆斯(J.Williams)在1964年共同发明,是一种精妙的排序算法。说说我对堆排序的理解,堆排序的时间复杂度是θ(nlogn),速度达到比较排序的下界,速度快那是不言而喻的。其基本思想是引入堆这种数据结构,通过堆的特点进行排序。也就是说堆排序的算法包含两部分——堆的建立和堆排序。那么复杂度将是两者的最差的那部分时间复杂度。所以,要找一个容易建立,又要容易排序的数据结构,但首要的是你要先想到将原数据转换为某种特殊的数据结构再来排序,我想这种思想才是其最精妙的地方。相信堆排序出来之后,各种数据结构都要被尝试一遍,所以要想用这种思想找到更块的排序算法,就要先发明一种新的数据结构。
表达完我对堆排序算法的敬仰之情,我们来看看堆这种数据结构。
多说两句,堆我们见到比较多的情况是在操作系统中,经常会看到“堆栈”。很奇葩的是百度百科和维基百科竟然有两种解释(看到后面发现其实在操作系统中只有一种解释)。个人觉得这要根据具体的情况来区分,比如堆的英文是heap,而栈是stack。准确来说,操作系统中一般指的是stack,而经常称作“堆栈”,而如果是指数据结构,则堆是堆,栈是栈,是完全不同的两种概念。
这里的堆结构是二叉树型的,当然还有斐波那契堆等。介绍一下最大堆,最大堆即除了根节点,每个节点都小于其父节点,最小堆相反。那么最大堆的好处便显而易见了,它的根节点是整个结构中最大的。(下图括号是数字在数组中的标号)
16(0)
/ \
14(1) 10(2)
/ \ / \
8(3) 7(4) 9(5) 3(6)
/ \ /
2(7) 4(8)1(9)可以看到,堆结构在二叉树下的样子,而在数组中数据是“之”字形排列的。
16 14 10 8 7 9 3 2 4 1max_heapify函数保证局部结构中最大堆的性质:
void max_heapify(int arr[], int i, int heap_size)
{
int l = left(i);
int r = right(i);
int largest, swap;
if ((l < heap_size) && (arr[l] > arr[i]))
largest = l;
else
largest = i;
if ((r < heap_size) && (arr[r] > arr[largest]))
largest = r;
if (largest != i) {
swap = arr[i];
arr[i] = arr[largest];
arr[largest] = swap;
max_heapify(arr, largest, heap_size);
}
}
left和right函数返回该节点的左节点和右节点的标号。我们来分析一下这个过程的时间复杂度。节点,则遍拿根节点来说,如果左节点大于根历整个做节点,那么最坏情况则是由左节点的规模(左子树的大小)来决定,最坏情况则是最底层恰好半满,即左子树在最下一层叶节点全满,最多2n/3。那么运行时间为:
T(n) = T(2n/3) + O(1)根据主定理,得到T(n) = O(logn)。
建立堆结构过程便很简单了,从最后非叶节点的节点开始,位置为n/2向下取整(可以证明叶节点是从此处开始)。依次向上使用max_heapify函数遍历其他非叶节点节点即可。容易得到复杂度为nlogn,其实可以得到更紧的界,具体请参考《算法导论》第二版78页,最后可以的得到建立堆的时间复杂度为O(n)。代码如下:
void build_max_heapify(int arr[], int heap_size)
{
int i;
for (i = (heap_size - 1) / 2; i >= 0; i--)
max_heapify(arr, i, heap_size);
}
堆排序过程即根据最大堆的性质,从最后一个节点开始,用该节点与根节点交换(根节点最大)后,将最后的节点删除(缩短堆的大小即可),再对新的堆进行处理使其保证最大堆性质。重复这一过程至根节点(不包括根节点)。代码如下:
void heap_sort(int arr[], int max)
{
int i, swap;
int heap_size = max;
build_max_heapify(arr, heap_size);
for (i = max - 1; i >= 0; i--) {
swap = arr[0];
arr[0] = arr[i];
arr[i] = swap;
heap_size--;
max_heapify(arr, 0, heap_size);
}
}
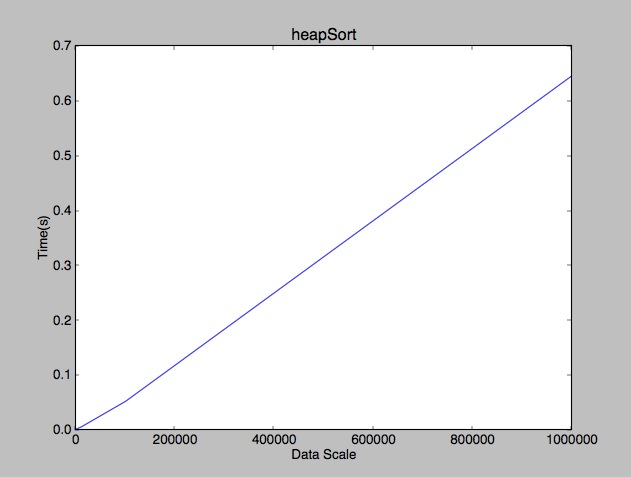
复杂度是n+nlogn,即nlogn。
到此算是把堆排序的一些基本原理讲了一下,代码都是简单的实现了《算法导论》中的伪代码,不过还是要注意边界的处理。
blog comments powered by Disqus